Page 1 of 1
[SOLVED] Using Switch for automatic OCR recognition?
Posted: Fri Jul 31, 2020 9:06 am
by magnussandstrom
Hi, we have a large project were we scan documents and make them searchable with OCR 'overlay' and save as PDF/A. Today we're using Acrobat Pro DC and made an Action in the Action Wizard that batch-run a folder of files. But since the project is so big and I want to automate this process.
Is there a way to setup a Switch flow (2020 spring release) for automatic OCR recognition from scanned pages and output as PDF/A?
After some googling I can't find any obvious solution. But maybe it's possible to do it with Switch and Acrobat PRO DC or maybe install Tesseract with some ingenious scripting? Any idéas?
And sorry if this has been asked before, but I'n not allowed to search for OCR (three letter word) in this forum..
Best regards,
Magnus
Re: Using Switch for automatic OCR recognition?
Posted: Fri Jul 31, 2020 9:22 am
by freddyp
Tesseract was also the first thing that sprang to my mind. Ingenious scripting? Tesseract is a command line tool, so you can integrate it with "Execute command". If the options are always the same, and I would think they probably are, you do not need a script. If the choice of options is more involved because of some if-then-else logic, it is not a lot of work for a Switch script developer to do that and if the project is that big, then that would be money well spent.
Re: Using Switch for automatic OCR recognition?
Posted: Fri Jul 31, 2020 9:33 am
by magnussandstrom
The options is always the same (no ifttt). Tesseract seems to only support image files and we output multipage PDF's from out scanner. This could probably be solved with Ghostscript etc.
Maybe I was hoping for a out-of-the-box solution. I'm guessing I'm not the first to do this in Switch?
I also found a few softwares like OCRvision that seem's to do what I want..
Re: Using Switch for automatic OCR recognition?
Posted: Fri Jul 31, 2020 12:25 pm
by Padawan
I've automated Tesseract before.
It indeed has the limitation that you can only input jpeg files, which makes that you can't input multipage PDF's. However, you should be able to build a flow which solves this without any scripting:
- Input folder where multi page pdf's are dropped
- Remember the original filename and the amount of pages in private data
- PitStop PDF2Image (or another tool) to convert the PDF to jpegs
- OCR the jpeg's via tesseract
- Use an assemble job with custom scheme. Job identifier is the original PDF filename which is stored in private data and the amount of files is the original amount of pages which is also stored in private data
- Use Merge PDF to merge the PDF's
Output should be a multipage OCR'd PDF.
These are the execute command settings I have:
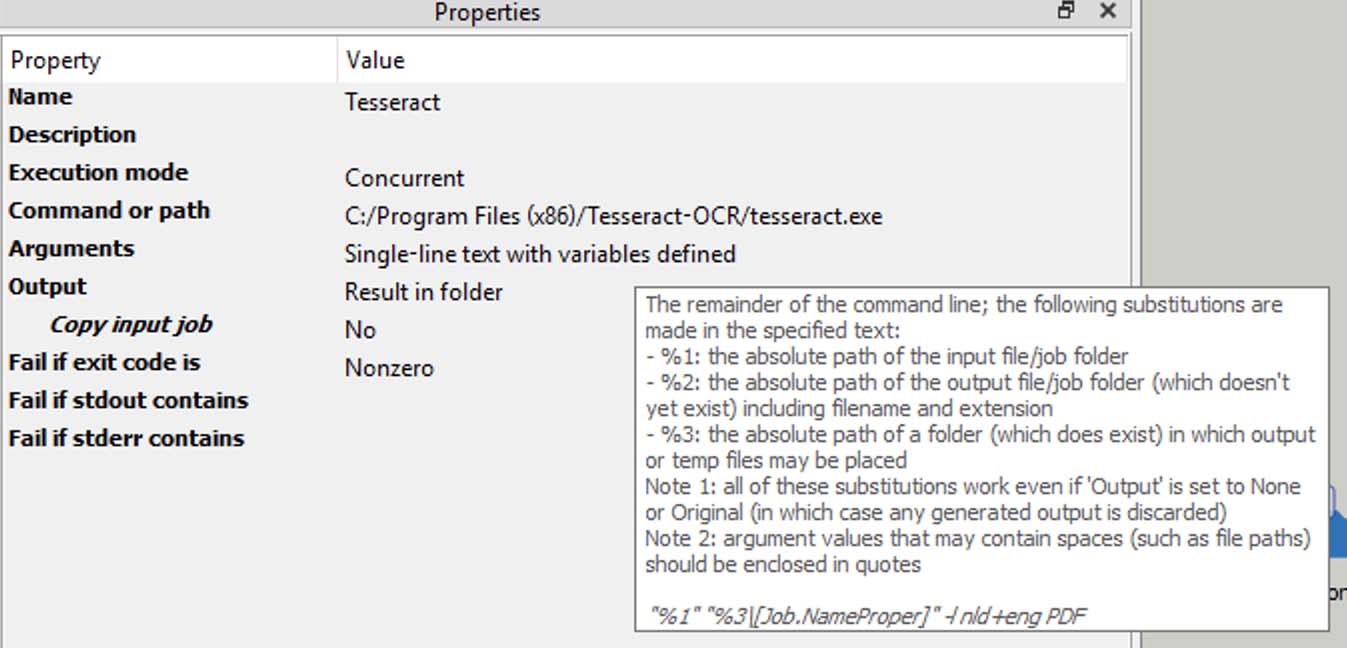
- Screenshot 2020-07-31 at 12.02.43 copy.jpg (91.85 KiB) Viewed 20866 times
Switch is more a build-it-yourself solution instead of an out-of-the box solution. There is more effort required compared to out of the box solutions, but it can do so much more. That's what makes it so awesome

Re: Using Switch for automatic OCR recognition?
Posted: Fri Jul 31, 2020 1:11 pm
by magnussandstrom
Thanks Padawan I will give it a try!
Re: Using Switch for automatic OCR recognition?
Posted: Fri Jul 31, 2020 4:06 pm
by magnussandstrom
I think I almost have figured it out, but I'm stuck att the assemble step.. The PDF-files doesn't contain the private data anymore.
Re: Using Switch for automatic OCR recognition?
Posted: Fri Jul 31, 2020 4:15 pm
by jan_suhr
Have you tried the property "Merge Metadata" and set it to Yes in the Assemble job.
Re: Using Switch for automatic OCR recognition?
Posted: Fri Jul 31, 2020 4:52 pm
by magnussandstrom
jan_suhr wrote: ↑Fri Jul 31, 2020 4:15 pm
Have you tried the property "Merge Metadata" and set it to Yes in the Assemble job.
Yes and I get the same result. I've tried to ungroup the job after Pitstop2Image and tried to use the Ungroup job in the Assemble-element with no luck as well.
Re: Using Switch for automatic OCR recognition?
Posted: Fri Jul 31, 2020 4:58 pm
by Padawan
Can you let the job move step by step thru the flow by placing connections on hold and this way test in which element the private data gets lost? You can check the contents of the private data via "Inspect jobs"
Re: Using Switch for automatic OCR recognition?
Posted: Fri Jul 31, 2020 5:16 pm
by magnussandstrom
Padawan wrote: ↑Fri Jul 31, 2020 4:58 pm
Can you let the job move step by step thru the flow by placing connections on hold and this way test in which element the private data gets lost? You can check the contents of the private data via "Inspect jobs"
It's working now! I found a typo in one of the PrivateData-parameter in the Assemble-element while checking were the private data got lost...

Thanks for all your help - Great first impression of this forum!
/ Magnus
Re: Using Switch for automatic OCR recognition?
Posted: Fri Jul 31, 2020 5:26 pm
by jan_suhr
Great, now you can sleep well on your vacation

Re: Using Switch for automatic OCR recognition?
Posted: Fri Jul 31, 2020 9:11 pm
by magnussandstrom
Thanks Jan!

Here is the final Flow for anyone looking for a solution to this in the future.
Tesseract (v5.0) installer can be downloaded here:
https://github.com/UB-Mannheim/tesseract/wiki
Switch flow: